Junhao Chen
Tsinghua University
3D/4D World Modeling & Spatial Intelligence · Generative Modeling for Structured & Controllable Worlds
Research Interests & Opportunities
👋 I am a master’s student at Tsinghua University, supervised by Prof. Ruqi Huang (expected graduation: Fall 2027).
Before Tsinghua, I graduated first in my class (rank 1/233, B.S. in Software Engineering) from Harbin Engineering University.
My Google Scholar:

My research goal is to build generative world models that can represent, generate, verify, and improve digital and physical worlds.
🔥 Actively seeking PhD positions (Fall 2027) and RA / visiting student opportunities. I am especially interested in advisors and collaborators working on world models, 3D/4D vision, video generation, code generation, LLM/VLM agents, auto research, and AI for robot / CAD / hardware design.
💼 I also have professor friends recruiting Research Interns (Beijing / Hangzhou / Shenzhen / Shanghai, competitive salary), MS/PhD students, and undergraduate research interns. If you are interested in 3D / VLM / video / animation generation and understanding, feel free to contact me! junhao-c24@mails.tsinghua.edu.cn
Feel free to contact me by email if you’d like to discuss or collaborate. 欢迎优秀的本科/研究生联系科研合作!
😥 Click here to enter emo time !
News
🔥 News
- 2026.06: 2 papers at ECCV 2026 - One Video One World, Multi-Speaker VSR. See you in Malmö, Sweden 🇸🇪!
- 2026.04: 1 papers at ACL 2026 — PairCoder. See you in San Diego 🇺🇸!
- 2026.02: 3 papers at CVPR 2026 — LottieGPT, HVG-3D, Skeleton-Gen. See you in Denver 🇺🇸!
- 2026.02: From Frames to Sequences released.
- 2026.01: 2 papers at ICLR 2026 — GarmentGPT, DanceTogether. See you in Rio 🇧🇷!
- 2025.12: 1 papers at Machine Vision and Applications — Ultraman.
- 2025.11: 1 papers at EMNLP 2025 — LLMsPark. See you in Suzhou 🇨🇳!
Selected Work
Representative publications and projects.
Work across 3D world modeling, interactive video, and controllable character generation.
📝 Publications
🧭 3D/4D World Modeling, Spatial Intelligence, and Embodied AI
World Representation, Articulation, and Spatial Intelligence

Feedforward 3D Editing Learns from Semantic-Part Transformation
Jiawei Weng *, Saining Zhang * †, Zhenxin Diao *, Peishuo Li, Henghaofan Zhang, Junhao Chen, Hao Zhao †
- PartFlow is a feedforward 3D editing network trained on Pxform, editing an existing 3D asset to match a target edit image without per-asset optimization or 3D masks at inference.

One Video, One World: Turning Monocular Video into Physical 4D Scenes
Junhao Chen *, Boran Zhang *, Mingjin Chen, Henghaofan Zhang, Saining Zhang, Congcong Zhu, Hao Zhao, Ruqi Huang †, Zhihao Li, Yufei Wang †


- OVOW is a fully training-free system that turns a single monocular video into an instance-level, simulation-ready 4D mesh scene for downstream embodied AI and physics engines.
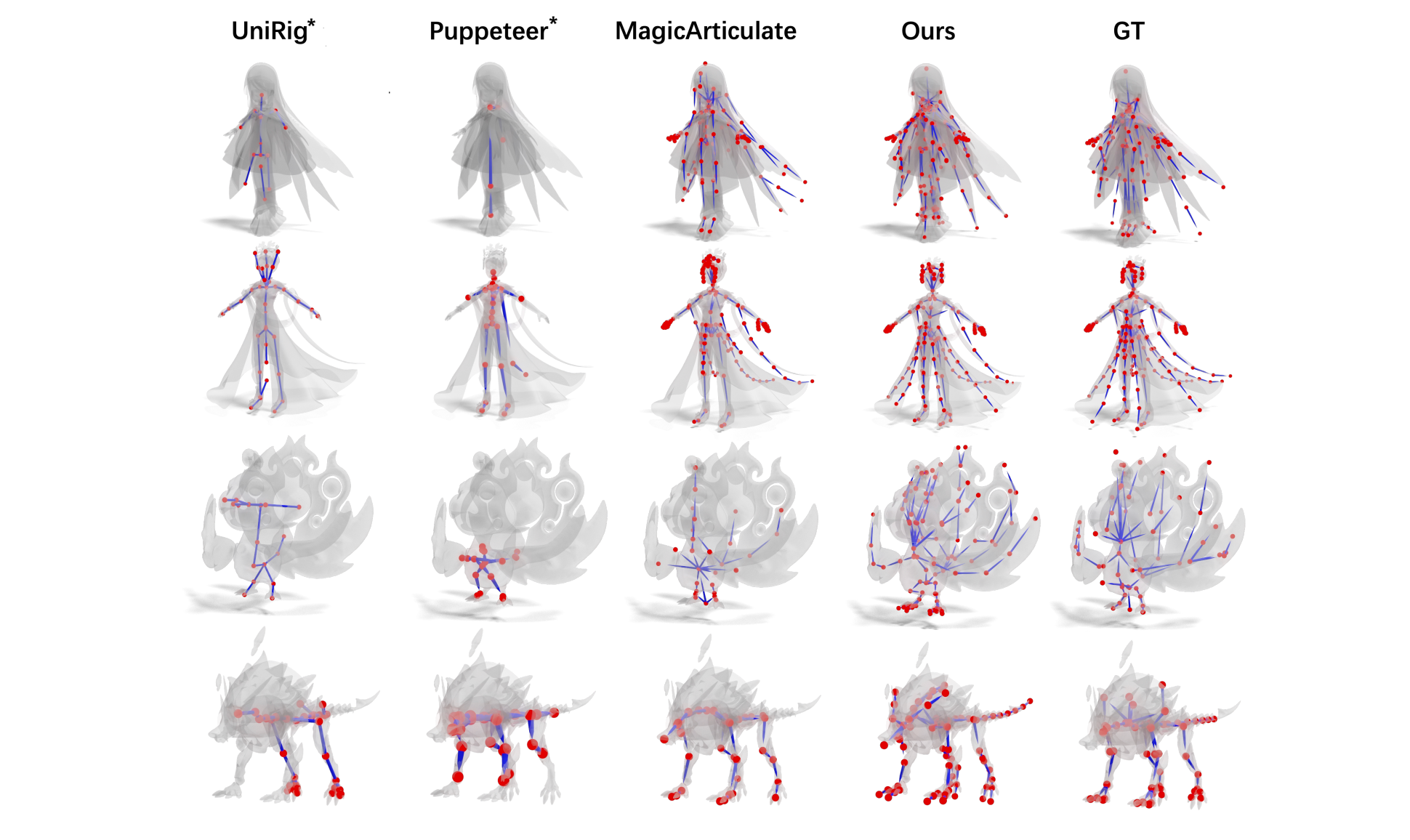
Animator-Centric Skeleton Generation on Objects with Fine-Grained Details
Mingze Sun, Cheng Zeng, Jiansong Pei, Junhao Chen, Chaoyue Song, Shaohui Wang, Tianyuan Chang, Bin Huang, Zijiao Zeng †, Ruqi Huang †
- Uses semantic-aware tokenization, a large rigged-mesh corpus, and a density-control module to generate high-quality, controllable skeletons for complex 3D assets.
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
Mingze Sun *, Junhao Chen *, Junting Dong †, Yurun Chen, Xinyu Jiang, Shiwei Mao, Puhua Jiang, Jingbo Wang, Bo Dai, Ruqi Huang †


- This work generates skeleton and skinning with clothes and hair for 3d gaussian avatar!
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mingjin Chen *, Junhao Chen *, Huan-ang Gao, Xiaoxue Chen, Zhaoxin Fan †, Hao Zhao †


![]()
- This work converts a single image of the human body into a lifelike 3D model!
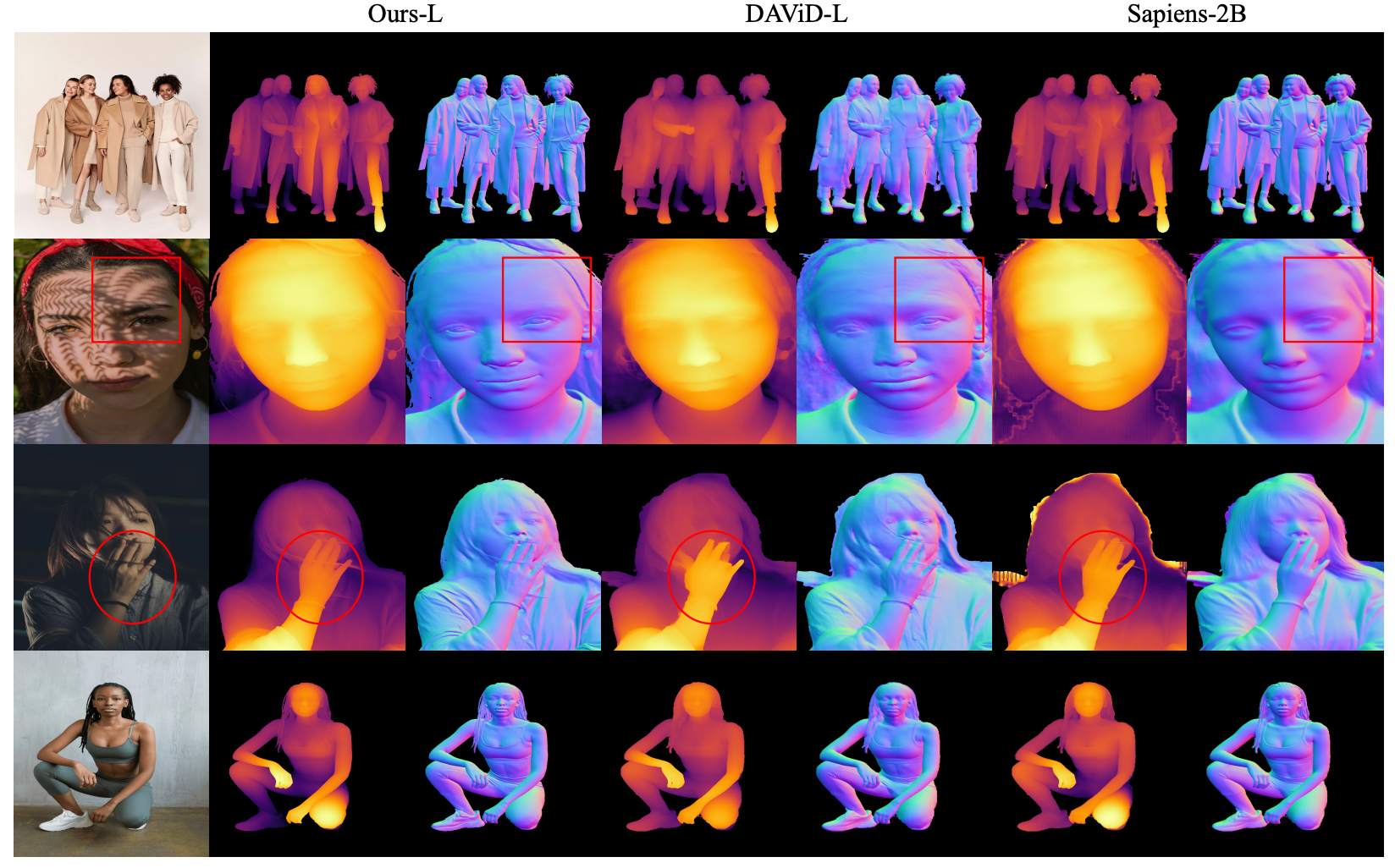
From Frames to Sequences: Temporally Consistent Human-Centric Dense Prediction
Xingyu Miao, Junting Dong †, Qin Zhao, Yuhang Yang, Junhao Chen, Yang Long †
- Learns temporally consistent human-centric segmentation, depth, and normals via synthetic video supervision and a two-stage static→dynamic training pipeline.
Interaction-Aware Embodied World Modeling
HVG-3D: Bridging Real and Simulation Domains for 3D-Conditional Hand-Object Interaction Video Synthesis
Mingjin Chen *, Junhao Chen *, Zhaoxin Fan †, Yujian Lee, Zichen Dang, Lili Wang, Yawen Cui, Lap-Pui Chau , Yi Wang †

- HVG-3D: A 3D-aware HOI video diffusion framework with 3D ControlNet that turns one image plus 3D control signals into spatially precise, temporally coherent interaction videos.
 DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
Junhao Chen, Mingjin Chen, Jianjin Xu, Xiang Li, Junting Dong †, Mingze Sun, Puhua Jiang, Hongxiang Li, Yuhang Yang, Hao Zhao †, Xiaoxiao Long, Ruqi Huang †


- This work generates identity-preserving multi-person interactive dance videos with controllable motion and appearance!
🎛 Generative Modeling for Structured and Controllable Worlds
Structured and Multimodal Content Generation
LottieGPT: Tokenizing Vector Animation for Autoregressive Generation
Junhao Chen *, Kejun Gao *, Yuehan Cui, Mingze Sun, Mingjin Chen, Shaohui Wang, Xiaoxiao Long, Fei Ma, Qi Tian, Hao Zhao †, Ruqi Huang †


- Tokenizes Lottie vector animations and finetunes a multimodal model to generate coherent, editable vector animations from text or visual prompts.
GarmentGPT: Compositional Garment Pattern Generation via Discrete Latent Tokenization
Fangsheng Weng *, Junhao Chen *, Xiang Li, Jie Qin, Hanzhong Guo, Shaochun Hao, Xiaoguang Han †
- Uses RVQ-VAE tokenization and a VLM generator to produce garment sewing patterns from discrete latent tokens, achieving strong accuracy on large curated datasets.
Idea23D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Junhao Chen *, Xiang Li *, Xiaojun Ye, Chao Li, Zhaoxin Fan †, Hao Zhao †


- This work enables automated 3D model design and generation for people!
Controllable Visual Generation

FineStyler: Text-guided Instance-level Fine-grained Image Style Transfer
Junhao Chen, Rong Peng, Xiang Li, Jingbo Sun, Hao Zhao, Ruqi Huang

![]()
![]()
- This work enables fine-grained stylization of a single image through text-guidance!
🎙 Multimodal Perception and Understanding
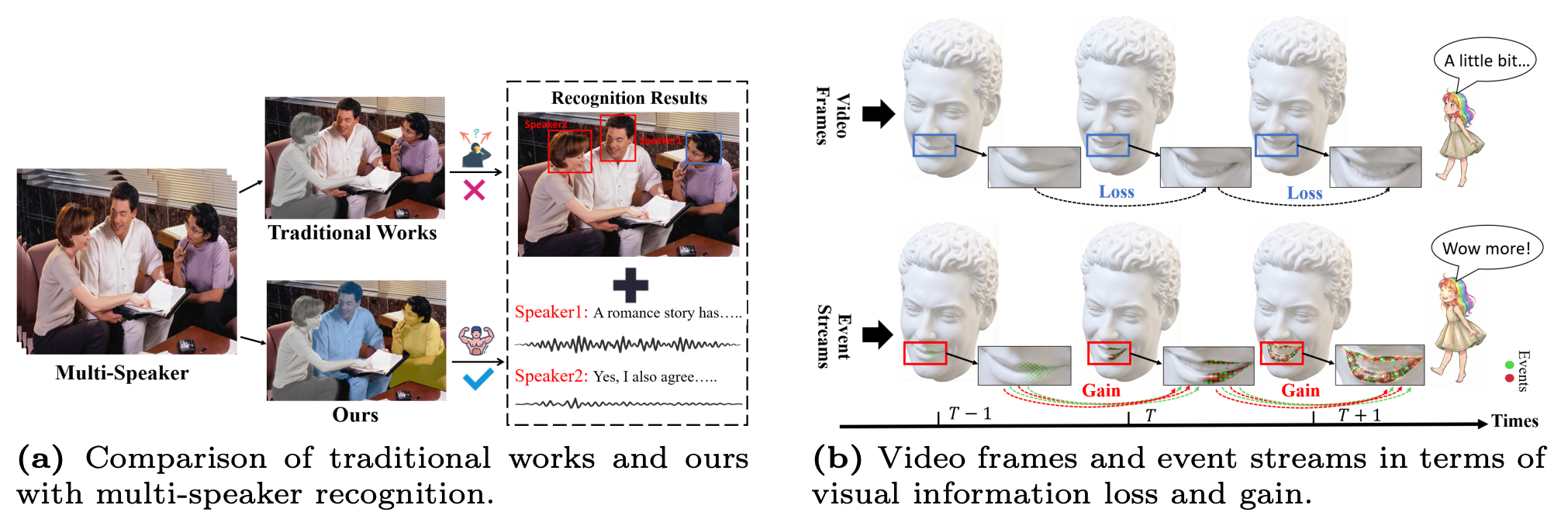
A First Exploration of Neuromorphic OT-CFM for Multi-Speaker VSR
Lin Chen, Jingping Fang, Hairui Liu, Chenyang Xu, Junhao Chen, Xiaorui Li, Weidong Cai, Xiaoming Chen
- LipsFlow tackles multi-speaker visual speech recognition by converting RGB videos into event streams and modeling fine-grained articulatory dynamics with efficient OT-CFM inference.
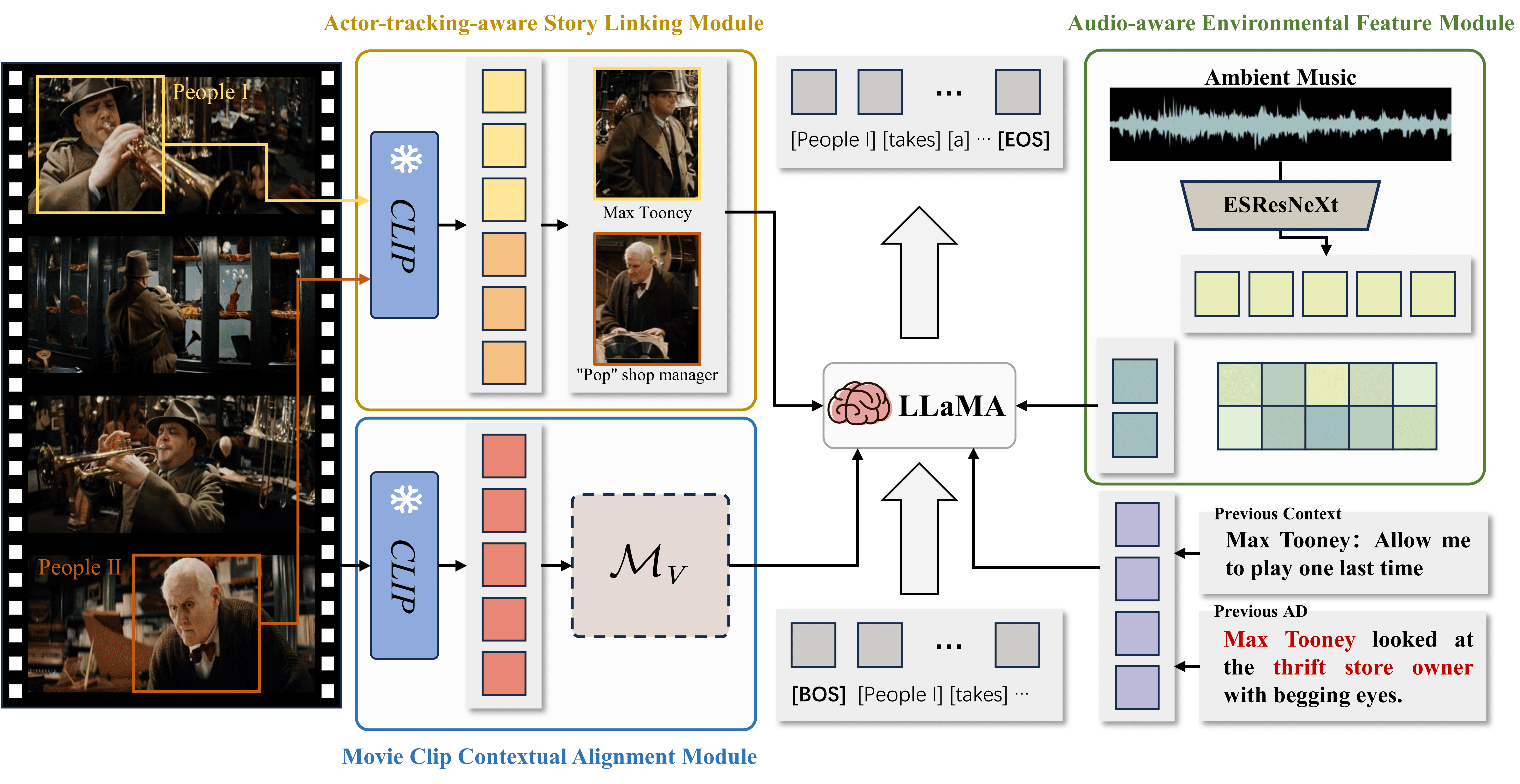
MMAD: Multi-modal Movie Audio Description
Xiaojun Ye, Junhao Chen, Xiang Li, Haidong Xin, Chao Li, Sheng Zhou †, Jiajun Bu


- This work has unlocked a whole new experience of watching movies for the visually impaired.
🧠 Foundation Models, Reasoning, and Evaluation
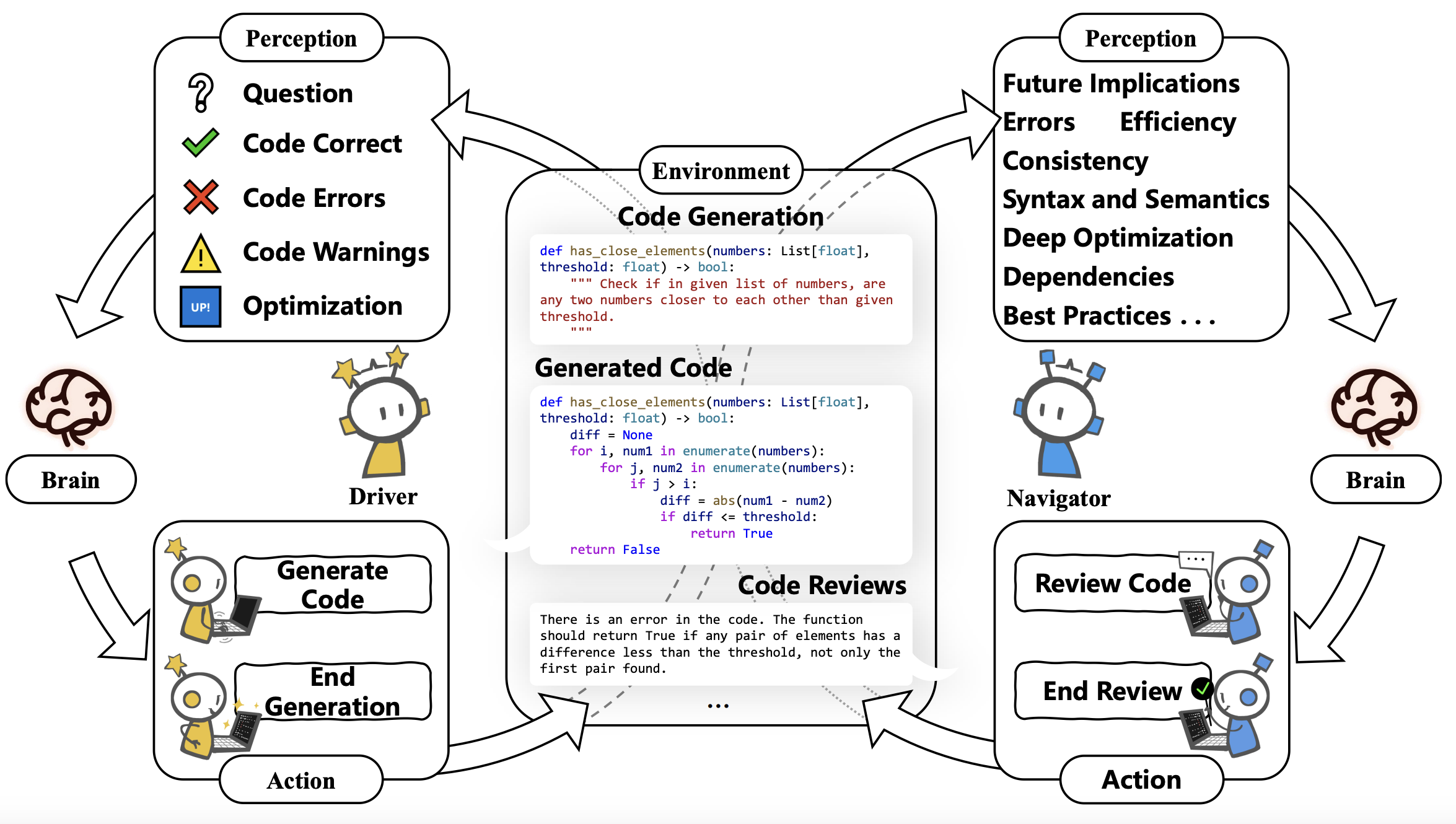
PairCoder: Pair Programming-Inspired Two-Agent Collaboration for Code Generation
Junhao Chen, Xiang Li, Yibin Xu, Yuehan Cui, Fangsheng Weng, Hao Zhao, Fei Ma, Qi Tian


- PairCoder adapts pair programming into efficient two-agent LLM collaboration, using dynamic Driver-Navigator interaction to improve code generation quality with far lower token cost than typical multi-agent frameworks.
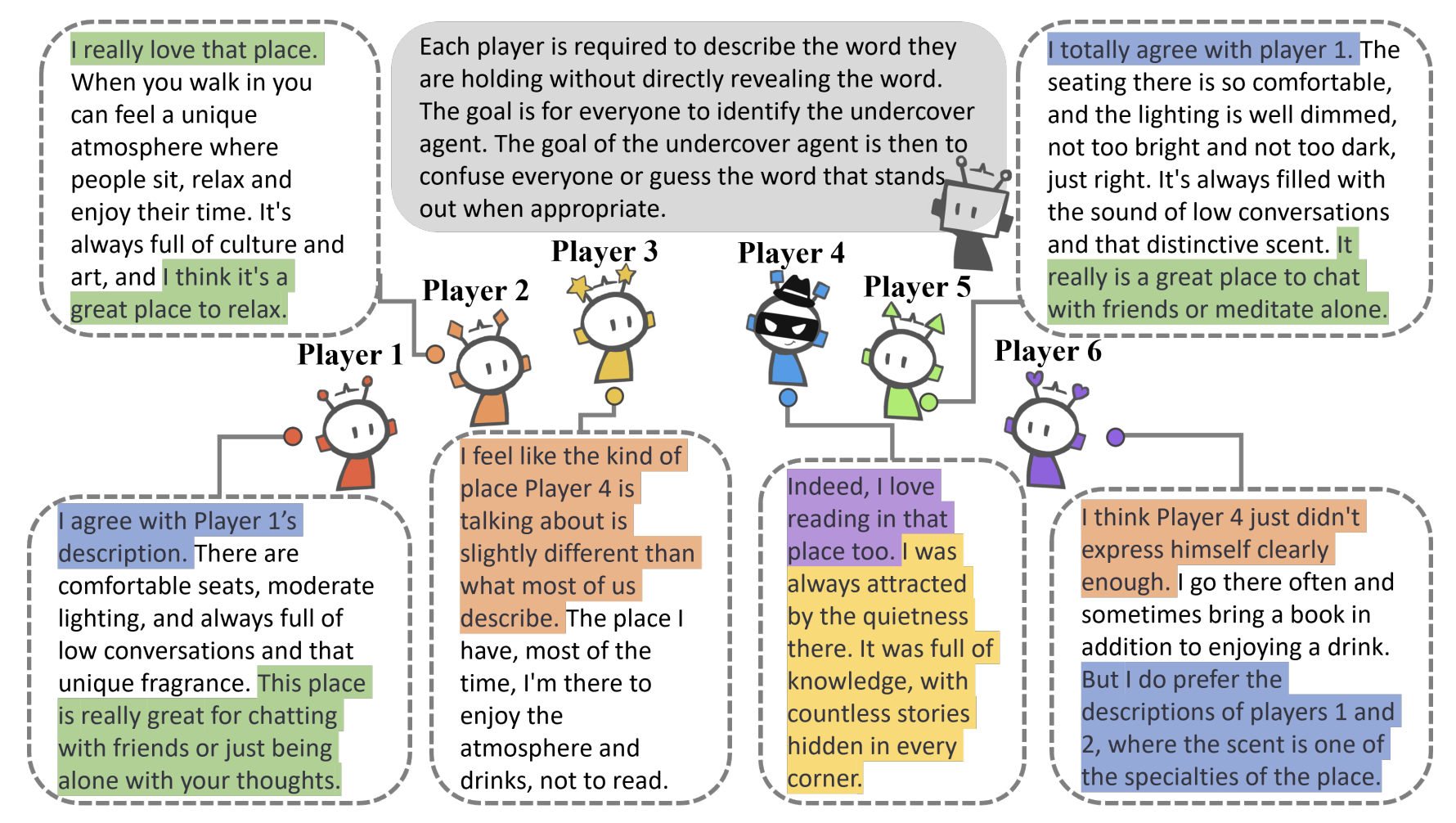
LLMsPark: A Benchmark for Evaluating Large Language Models in Strategic Gaming Contexts
Junhao Chen, Jingbo Sun, Xiang Li, Haidong Xin, Yuhao Xue, Yibin Xu, Hao Zhao †

![]()
- This work evaluates LLMs through a game-theoretic framework.

IW-Bench: Evaluating Large Multimodal Models for Converting Image-to-Web
Hongcheng Guo, Wei Zhang, Junhao Chen, Yaonan Gu, Jian Yang, Junjia Du, Shaosheng Cao, Binyuan Hui, Tianyu Liu, Jianxin Ma, Chang Zhou, Zhoujun Li


![]()
- This work is a benchmark for evaluating MLLM image-2-html code generation capabilities.
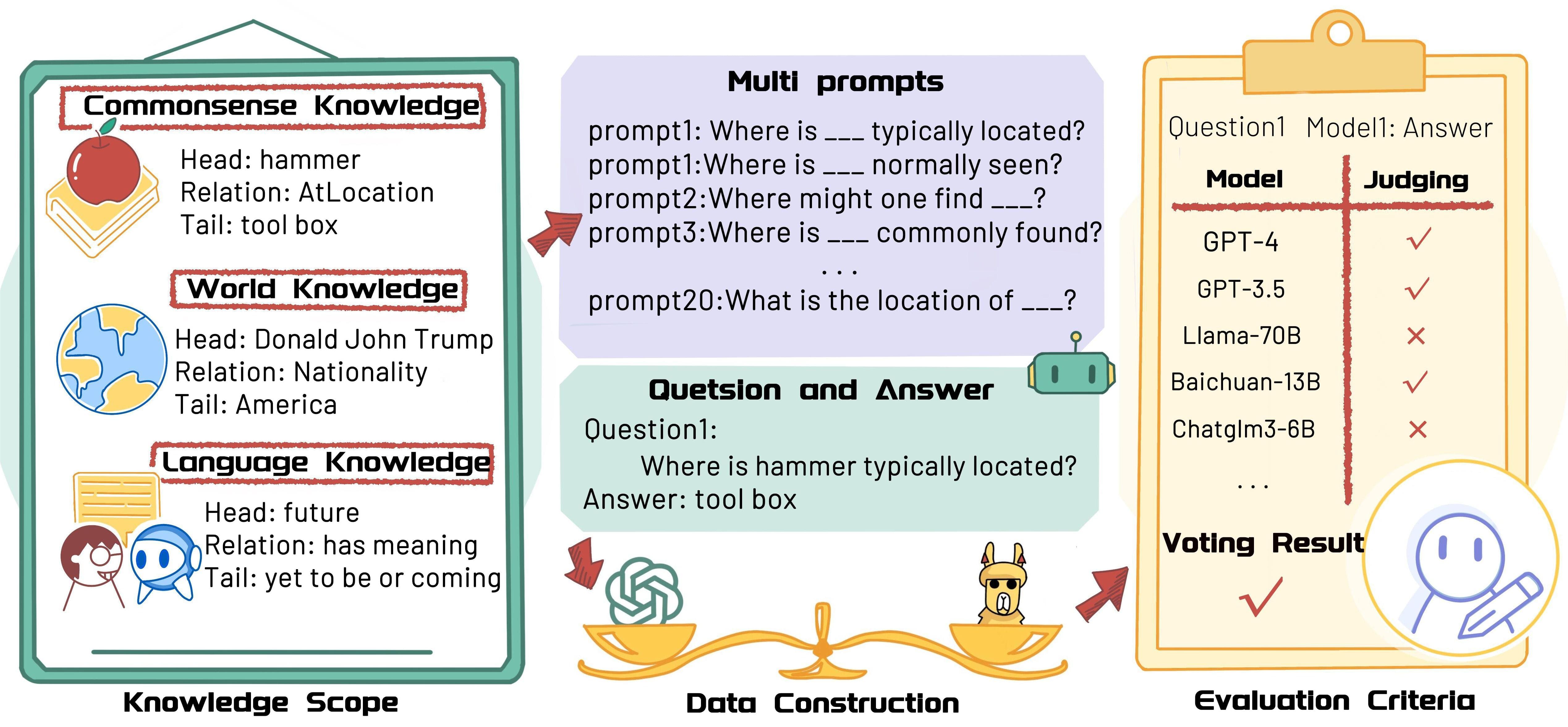
ZhuJiu: A Multi-dimensional, Multi-faceted Chinese Benchmark for Large Language Models
Baoli Zhang, Haining Xie, Pengfan Du, Junhao Chen, Pengfei Cao, Yubo Chen †, Shengping Liu, Kang Liu, Jun Zhao

![]() [📜Paper]
[🎥Video]
[📜Paper]
[🎥Video]
- This work serves as a benchmark for evaluating the Chinese language capabilities of large language models.
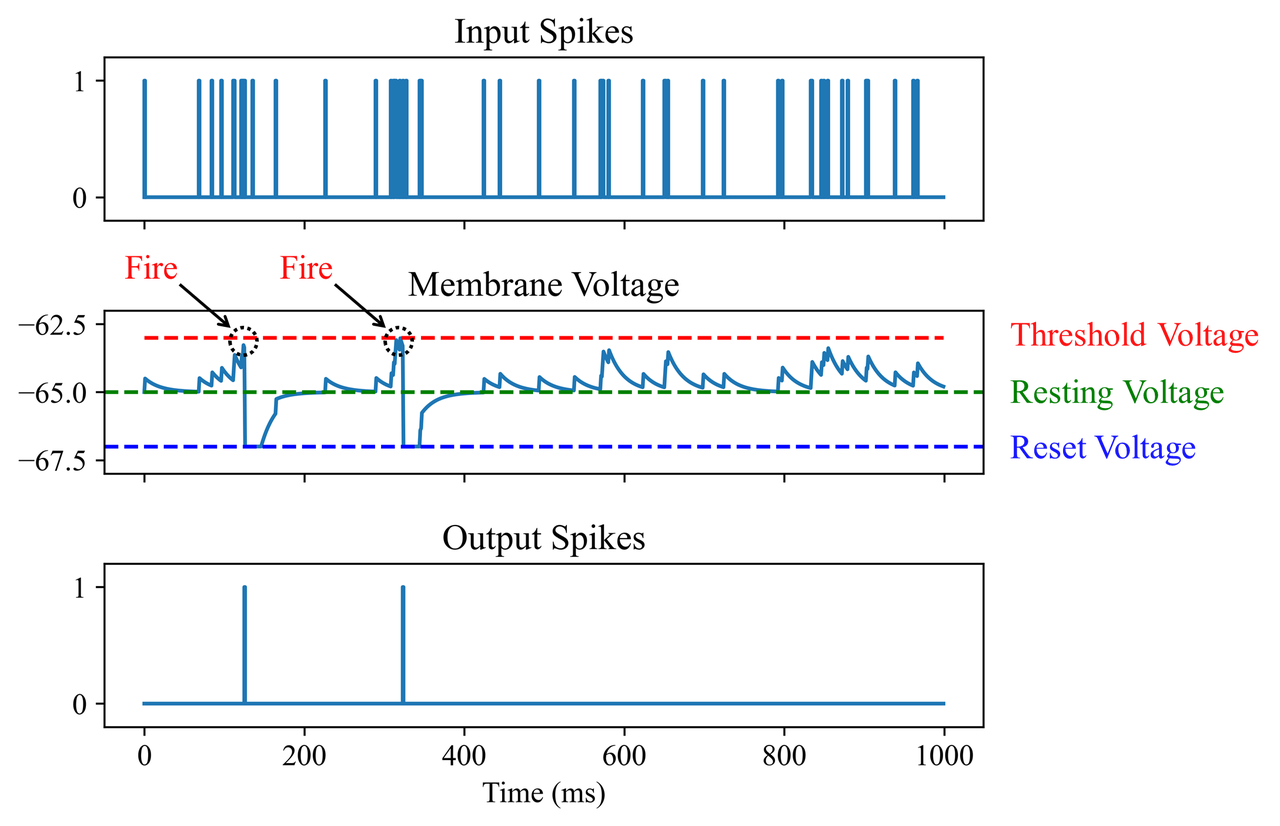
Towards Energy-Efficient Sentiment Classification with Spiking Neural Networks
Junhao Chen, Xiaojun Ye, Jingbo Sun, Chao Li †
- This work applies a pulsed neural network to a natural language sentiment categorization task, reaching the leading edge in terms of energy consumption.
Recognition
Honors, awards, and competition results.
Selected recognition from research and engineering work.
🎖 Honors and Awards
Innovation and Entrepreneurship Competition Award Cumulative Awards National *10, Provincial *45, School-level *11, totaling 66.
Honors awards cumulative awards national *6, provincial *2, school-level *20, a total of 28.
Competition awards and individual honors total 94 (as of 11, 18, 2024).
List of all awards received.
Journey
Education, research experience, and service.
The path that shaped the current research direction.
📖 Educations
- 2024.08 - 2027.06, M.Eng. in Data Science @ Tsinghua University, Shenzhen.
- 2020.09 - 2024.06, B.Eng. in Software Engineering (rank 1 / 223) @ Harbin Engineering University, Harbin.
💻 Experiences
- 2025.05 - 2026.02, Research Intern, Tencent Games, Shenzhen.
- 2025.01 - 2025.05, Research Intern, Shanghai AI Lab, Shanghai.
- 2024.09 - 2025.01, Research Intern, AIGrowthGroup@TAL Education Group, Beijing.
- 2024.06 - 2024.08, Research Intern, Lightillusions, Shenzhen.
- 2023.08 - 2024.05, Research Intern, DISCOVERLab@Institute for AI Industry Research (AIR), Tsinghua University, Wuxi.
- 2023.04 - 2023.08, Research Intern, National Lab of Pattern Recognition@Institute of Automation, Chinese Academy of Sciences, Beijing.
🧑💻 Professional Services
Reviewer@ACL ARR (2025.02 - now) ICLR (2026), AAAI (2026), ICML (Gold Reviewer with complimentary registration@2026), TMLR 2026, TVCG 2026, ECCV (2026), ACM MM (2026), NeurIPS (2026), SIGGRAPH Asia(2026)
Reach